 NISTからフィッシング訓練に関するドキュメントが出たので読んでみました。
NISTからフィッシング訓練に関するドキュメントが出たので読んでみました。
何の本?
皆さんの組織でも不審メール訓練的なものを実施していると思います。
NIST Phish Scaleとは、人の目によるフィッシングメールの検知の難易度を定量的に評価するために作成された手法であり、本書(NIST TN 2276 NIST Phish Scale User Guide)はその考え方を解説するものです。
構成は?
全39ページ、本文は17ページです。
後述の通り、スライド1枚で説明ができる分かりやすい構成になっています。
- はじめに
- NIST Phish Scaleの算出方法
- 算出結果の解釈
本書の日本語訳
勝手に私のブログでは頻出させていただいている丸山さんのブログで仮訳を公開されていたのでそちらを参考にさせて頂きました。
いつもありがとうございます。
NIST Phish Scaleは何に役立つのか
フィッシング訓練の実施者にとって、以下の効果があると書かれています。
NIST Phish Scaleの求め方
説明に入る前に、本書をスライド1枚で表すとこうなります。
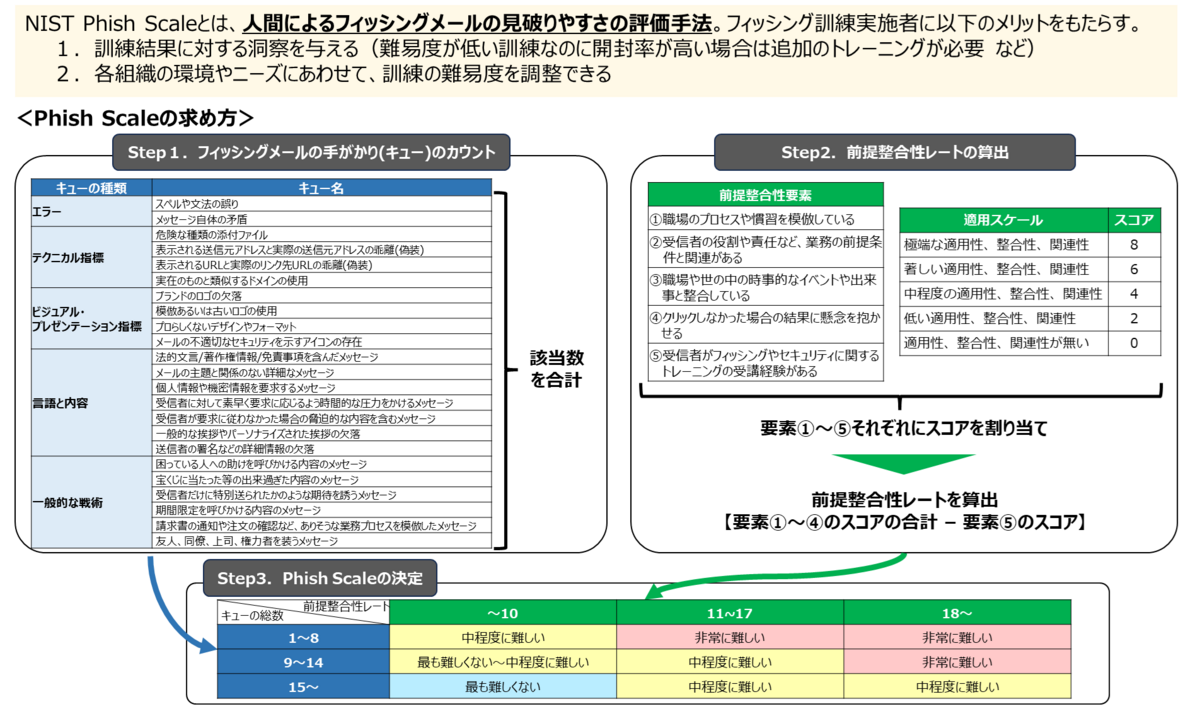
Step1とStep2をそれぞれ求めて、最終的にStep3で検出難易度(Phish Scale)が決まるのね~と分かれば大丈夫です。
Phish Scaleは、以下の大きく2つのスコアから決められます。
- メールに含まれる視覚的に確認できる不審な手がかりをスコア化したもの(メールキューの総数)
- メールの前提を受信者の状況や環境にどれだけ寄せているかをスコア化したもの(前提整合性レート)
Step1. メールキューのカウント
メールに含まれる不審な手がかり、つまりキューは5タイプ・23項目から成ります。
このキューが多いほど「いかにも不審なメール」と言えます。
各キューの内容とカウントの基準は以下の通りです。

いきなり細かい表ですみません。ただ、最後に書きますが個人的にこの表は大事だと思っています。
カウントの単位は、「YES/NOで切り分けてYESなら1点とするもの」と「スペルミスのように該当する数だけカウントするもの」の2種類あります。
例えば、メールに3つのスペルミスと2つの文法ミスがあった場合は、キューの総数は5つの「スペルと文法の不規則性」としてカウントします。
別の例として、メールにハイパーリンクを含むURLの記載があり、そのURLが「本物の組織の一文字違いのドメインを表記している」かつ「画面表示しているURLと実際にリンクされるURLが異なる」場合は、「スペルと文法の不規則性」と「URLのハイパーリンク」の2つのキューとしてカウントします。
集計したキューが8個以下ならキューが少ない(=見破りにくい)、15個以上ならキューが多い(=見破りやすい)、その間ならまぁまぁといった感じで捉えます。
Step2. 前提整合性レートの算出
前提整合性レートは、5つの要素から成り、各要素に対して5段階のスコアを割り振った上で後述する計算式に当てはめて求めます。
算出したレートが高いと、受信者の立場や環境上、不自然さを感じにくく「見破りにくいメール」となります。
前提整合性要素は以下のものがあります。
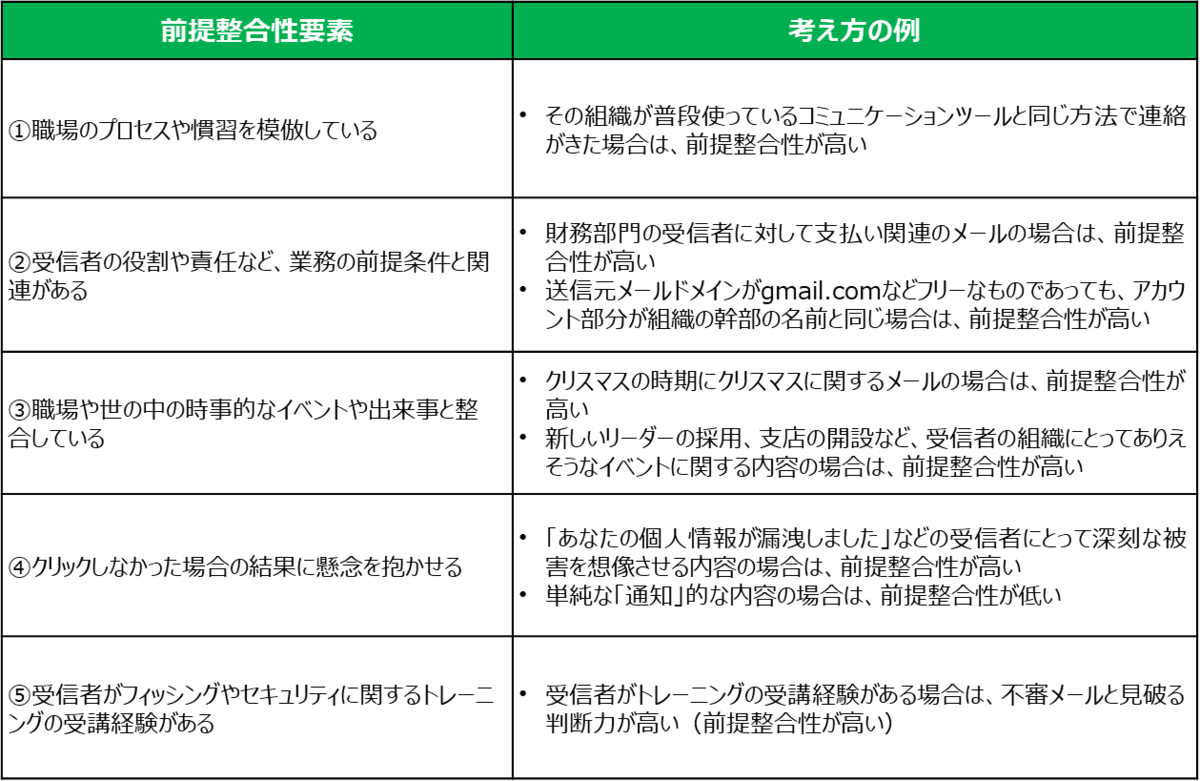
5段階のスコアは以下の考え方です。

各要素にスコアを割り振ったら、前提整合性レートを算出します。
上記5つの要素のうち、①~④は受信者が不審さを感じにくい要素でした。
かたや⑤は受信者のトレーニング経験という、①~④とは逆の意味を持つ要素でした。
よって、計算式は「要素①~④のスコアの合計 – 要素⑤のスコア」となります。
求められる前提整合性レートは -8~32の値になります。
値が10以下なら前提整合性が弱い(=見破りやすい)、18以上なら前提整合性が高い(=見破りにくい)、その間ならまぁまぁといった感じで捉えます。
Step3. 検出難易度の決定
Step1とStep2で求めたスコアやレートから検出難易度が決まります。
本書とはフォーマットが異なりますが、考え方は以下です。

あとはこれを使って、訓練結果を深堀したり、訓練の難易度を調整したり、色々役立ててみてね。という感じです。
まとめは以上です。
実のところ、私はPhish Scaleそのものにはそれほど価値を感じていません。
それは、こんなにゴチャゴチャと計算をせずとも見破りやすいかどうかなんて大体分かるし、精緻に検出難易度を測定・分類したいと思ったことがないからです。
「当社では『中程度に難しい』フィッシングメールを従業員のX%が見破れるようになるレベルを目指します!」とか宣言したところで誰もそのレベルでOKと判断できないし、実際に到達できるかどうかはコントロールできません。
結局、簡単なものから難しいものまで多種多様な事例を扱って従業員に「こういうのもあるんだ」と知ってもらう、そして実際にひっかかった時の動き方を知ってもらうしかないと思っています。
では何に価値を感じたのかというと、Step1や2で紹介した各要素についてです。
従業員に不審メールの教育をする際、「不審なメールってのはこういうところが不審なんだ」と不審ポイントを言語化する材料に使えそうだと思い、まとめました。